With the IoT becoming a reality, IT infrastructures and software systems get more and more complex while the need for their interoperability intensifies.
Interoperability spreads broadly over different IoT systems, layers and IoT-related sectors. For example, there are industries that request for or even need to enhance the information flow along their production value chain of Internet-Connected Objects to optimize the related workflows: this calls for efficiency and of course profit generally falls into the Industrial IoT domain. As another example, we could image an open market of information providers, e.g. sensor and platform owners, and information consumers, e.g. application provider, that want to co-operate and exchange data on a known basis or even in an ad-hoc manner.
All systems that need to be interoperable have something in common: they share a domain – otherwise interoperability would be useless as they have nothing in common to exchange.
For the software in a value chain, this could be the product the value chain is focused on, and for ad-hoc provider/consumer relations this could be the domain of the provided/requested data, e.g. temperature sensor readings or free parking spots in a city. Therefore, mutual understanding of this shared domain is crucial.
Unfortunately, this kind of information exchange a.k.a. interoperability is (most of the time) not possible without major extensions to existing systems. As every information exchange is an act of communication, let us compare this to two humans trying to communicate and exchange information in a written manner. Quite obviously, they should use the same language, which implies that they are using the same alphabet. ‘Using the same alphabet’ means that two entities, e.g. humans or computers, can exchange data (even if they don’t understand the meaning) just like someone can read an English text as long as he knows the Latin alphabet no matter if he understands the text or not. In the IT world, this is called syntactic interoperability and the alphabet consists of a number of API calls that can be used to read and write bits of data. ‘Using the same language’ means that two communicating entities are able to understand the meaning of exchanged data (which upon understanding becomes information rather than data). In IT, this is referred to as semantic interoperability and the languages are lists of agreed-upon terms called vocabulary or information model.
Direct communication in the same language is always the best, but not always possible or wanted. Imagine a UN meeting where everyone can use his/her mother tongue which is translated into all other languages. In these cases, communication is still possible as long as there is any kind of intermediary that is capable of translating between the languages. In the case of communication between humans speaking different languages, we perceive translation as something straightforward and reasonable. However, in the IT world the focus up to now is on ‘using the same language’ a.k.a. standardization. Unfortunately, almost all IT solutions approaching interoperability only achieve interoperability between systems by using the same vocabulary (or information model, the two terms are used as synonyms in the following). Additionally, they rather focus on creating such vocabularies for different domains and use cases than to provide support for translating between existing vocabularies or even arbitrary ones.
symbIoTe’s point of view is that having an agreed-upon (a.k.a. standardized) vocabulary is of course the perfect way and absolutely desirable. Nevertheless, this is not realistic, especially not in the very near future because the world is full of existing legacy systems that should now be interconnected and able to interoperate. Furthermore, each system serves a special, probably different purpose that comes with specific requirements. Therefore, different systems will have a different view (e.g. another level of detail) on the same domain. Using the least common vocabulary for the communication between all of them is not optimal, as two systems may be able to exchange more detailed information as they are both able to understand more details of the domain than others. In human communication, this compares to forcing two people to communicate using Esperanto even if they speak very similar languages like American English and British English and could understand each other better using their native languages.
In symbIoTe, we’re working towards not only supporting interoperability between IoT systems that use the same vocabulary (a.k.a. interoperability by standardization) but towards providing support for translating between the vocabularies/information models of different systems.
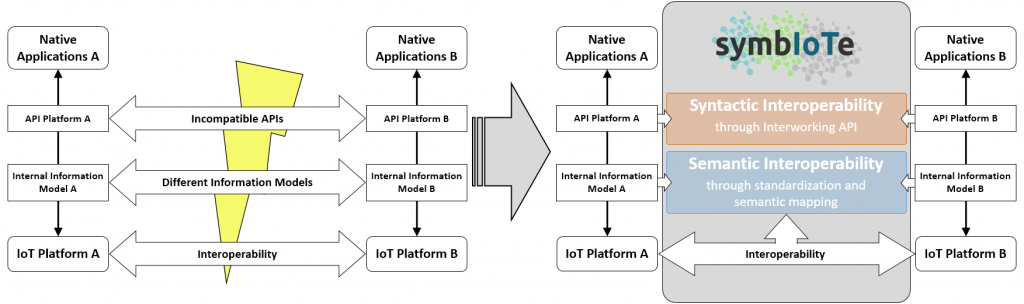
Many problems currently prevent interoperability in the current IoT landscape: incompatible APIs, substantial differences in information models, protocol interoperability problems just to mention a few major ones. symbIoTe is working on solving these issues with an interoperability framework capable to implement syntactic interoperability (through introduction of an interworking API) and semantic interoperability (through standardization in combination with support for semantic mapping).
Read more on how symbIoTe addresses semantic interoperability in our next posts where we will have a detailed view on what’s happening inside the blue box!
Michael Jacoby
Task leader of “Semantics for IoT and Cloud Resources”
 This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 688156
This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 688156